
Understanding Fluence: Introduction to Cloudless Concepts

Fluence is the first decentralized cloudless computing platform that provides an alternative to the internet oligopolists by removing the risks of centralized control. We designed and built Fluence from first principles, ensuring trustlessness via crypto-economic incentives and using cryptographic proofs to provide verifiability for all computations without sacrificing performance. This has resulted in one of the most innovative protocol designs on the market. In this blog post, I’ll walk you through the Fluence architecture and the novel concepts that constitute it and make the cloudless experience possible. I’ll also break down the steps we’ve taken to put this architecture into place.
Let’s dive in!
***
Fluence protocol constitutes a network made up of many compute peers that runs on hardware servers and is owned by multiple compute providers. This network, facilitated by the Compute Marketplace, is what enables an off-chain cloudless experience. Since Fluence is not a blockchain where nodes are assumed to be uniform, compute providers and peers participating in the network differ in capabilities.
Solving the network navigation and execution coordination challenges of cross-peer and cross-provider computations involves several steps:
- Initially locating the appropriate peer or set of peers on the network
- Directing the request to these identified peers
- Executing the Compute Function
The execution strategy could vary — for instance, it may be aimed at securing the quickest response for read queries, ensuring a defined fraction of acknowledgements are received, or enabling fault tolerance.
The distributed workflow of Cloudless Function includes routing from peer to peer, invoking a computation on peers, connecting outputs to inputs, retrying calls, handling timeouts, and other operations. The computing invoked on an assigned peer and producing outputs is called a Compute Function. When compute needs access to web2 services or web3 protocols, functions can interact with the external world using Managed Effects.
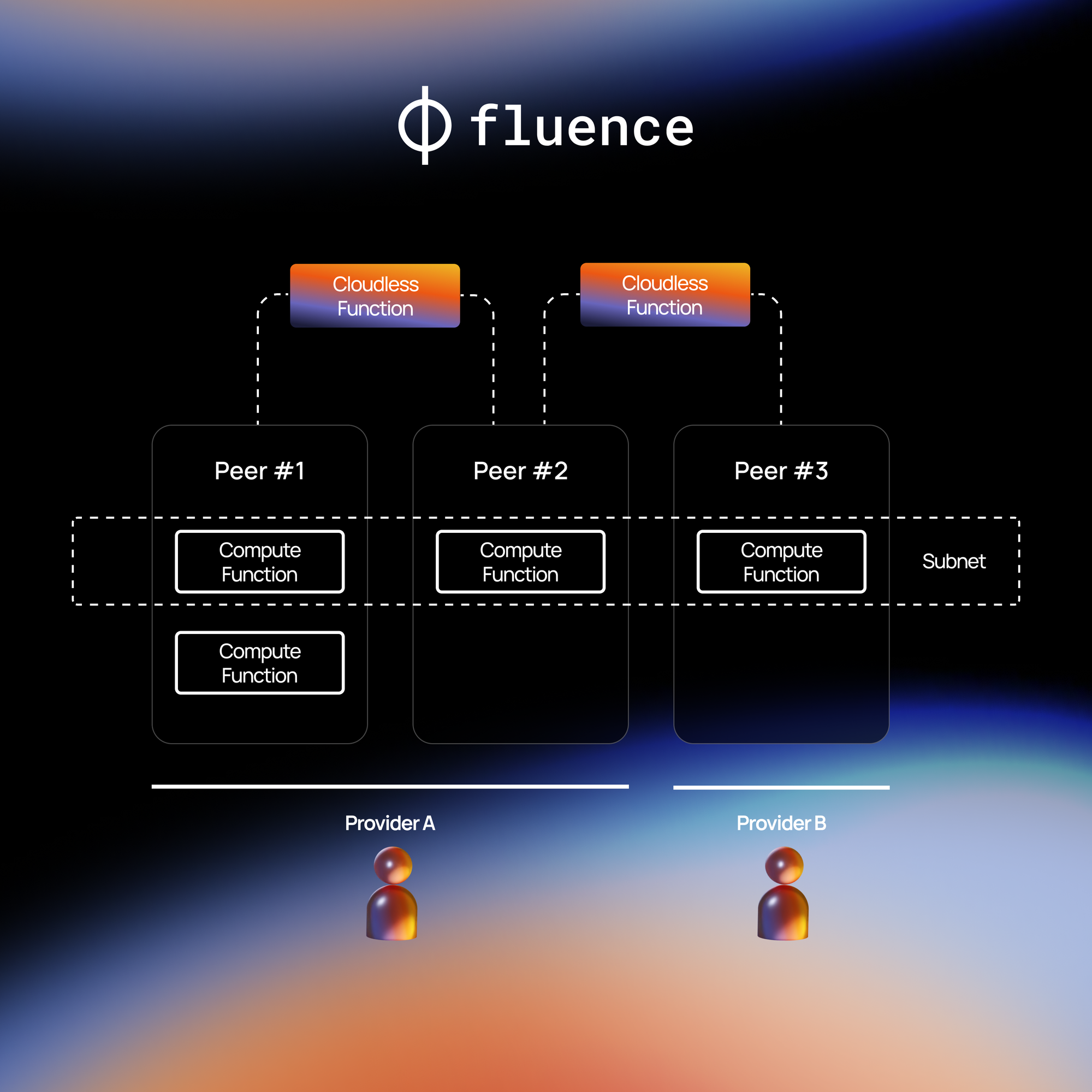
The three concepts: Cloudless Function, Compute Function, and Managed Effects, are the cornerstones of Fluence’s protocol design.
Cloudless Function
Cloudless is a decentralized serverless. There must be no single coordinator that might be managing computation requests. Such a bottleneck and a single point of failure would bring us back to the traditional cloud, losing many benefits of DePIN. Cloudless Functions are designed for distributed, coordinator-free choreography, which include parallel execution, fail recovery, on-demand quorum for execution results of BFT consensus.
Cloudless Functions are invaluable as they allow creating live distributed systems that may change or update behavior without complex redeployment, protocol node updates, or hardforks. Cloudless Functions are packaged into the peer-to-peer communication protocol and can be shot, updated, or removed by developers seamlessly. They define exactly how your compute routine is discovered, executed, secured, verified in the open distributed cloudless Fluence network.
To let developers prescribe and run distributed behavior of Cloudless Functions, Fluence innovated Aqua: a programming language and a runtime. Distributed workflows, defined in Aqua scripts, delegate computation to Compute Functions on selected peers which are discovered dynamically over the network during the execution.
Aqua, as both the language and the runtime, comes with certain guarantees, limitations, and flexibility benefits.
Guarantees include:
- No replay attack: there’s no way to intercept a Cloudless Function during its execution and reuse it in a way its originator didn’t set it to.
- No MitM attack: there’s no way to fake peers’ responses.
- Convergence: true parallelism with forking and joining can never end up with conflicting state of Cloudless Function.
- Audited execution: during each stage of distributed workflows, an audit log is created and checked. This process guarantees that the execution of the Cloudless Function adheres strictly to the developer's instructions.
Limitations include:
- Aqua only does choreography: the task of computation is delegated to the Compute Functions.
- Not a data plane: big chunks of data must be moved around with data-focused solutions or protocols.
- Learning curve: Aqua is a brand new special language that developers need to use for Cloudless Functions.
- Yet not so many library algorithms: you’ll likely need to implement the algorithm yourself.
Flexibility benefits include:
- Strong foundation: Aqua runtime (AquaVM+AIR) is implemented on top of π-calculus for distributed logic and lambda calculus for data manipulations, which means that almost anything that you can imagine is possible to implement as a part of Cloudless Function with Aqua.
- Execution strategies such as consensus, failover, load balancing, and others, once implemented, can be reused as Aqua libraries.
Many distributed systems require synchronization of participating peers about the application state to prevent failures or malicious actions, or to distribute the load across hardware resources. Cloudless Functions make it easy to implement such systems as easily as using library functions with configuration to fit your needs.
Cloudless Functions operate on top of pre-selected sets of peers, called Subnets. Subnets are necessary to synchronize the state or persistent logic, so peers working together know about each other. For example, to execute leader election or data synchronization for consensus algorithm, Cloudless Functions need to be independently initiated and hosted on certain Subnet peers, then one by one triggered by time or an event, and executed in a coordination round according to the algorithm.
Cloudless Scheduler does the job of triggering functions periodically by time or external events as defined by developers. It is useful for securing leadership in the Subnet, syncing data, pulling updates, or reacting to chain events to trigger a compute execution.
Compute Function
As Cloudless Functions are essentially distributed workflows that choreograph Compute Functions, the latter provide the actual compute job.
Given the nature of software, customer compute jobs can literally be anything: from simple function execution to complex business logic interacting with databases, protocols, web or storage. Compute providers who run those jobs must have their resources secured, so incoming jobs don't break their system accidentally or intentionally. One of the best ways to sandbox the customer code is by using WebAssembly.
Marine is the default compute runtime for Compute Functions, delivered as a part of Cloudless Deployment in the Fluence Network. Marine is a general purpose Webassembly runtime that supports Wasm Module Linking with a shared-nothing linking scheme. With the Marine runtime, developers can use any language that compiles to WASM, with some limitations needed for safety and portability.
To achieve safety, Marine restricts host imports: Marine’s Webassembly modules, by default, cannot trigger any external effect, open a socket, or execute a binary. Yet Marine makes an exception for capabilities provided by WASI system interface, such as reading a current host’s time or accessing file system.
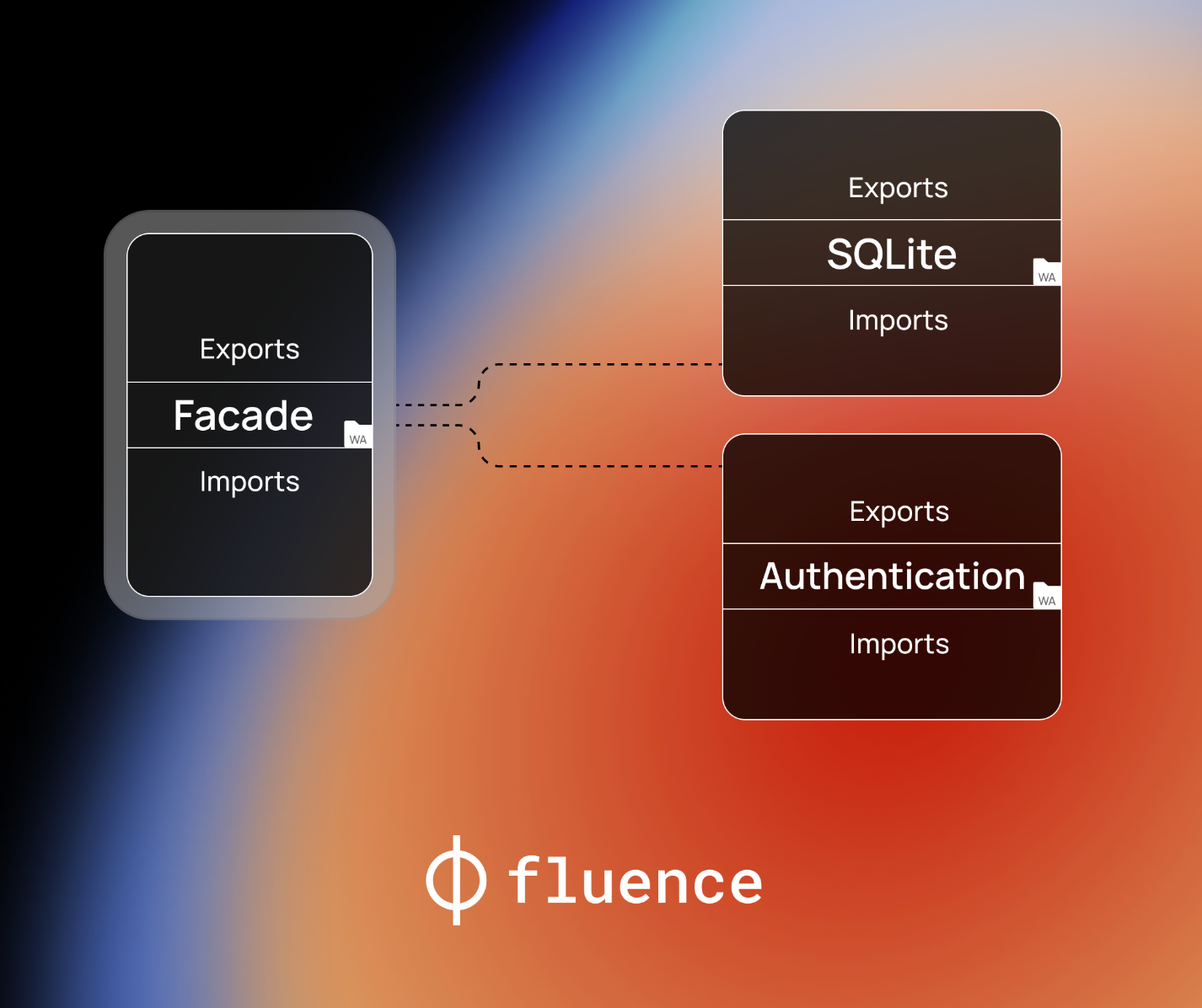
Marine configures a number of directories to be accessible by Marine modules. The majority of these directories are situated in ephemeral storage, which is essentially RAM. Any state in this storage is lost if the host machine restarts. While a limited amount of persistent storage is also provided, to ensure data durability developers are required to use replication across peers in the Subnet (via Cloudless Functions) and/or leverage external storage solutions.
Compute Function can be assembled from several Webassembly modules with the help of module linking. The module linking approach allows partial solutions to be crafted in any compatible language and distributed in the form of a content-addressable .wasm binary. This facilitates their reuse across numerous Compute Functions on the network.
Compute Functions are provided access to Cloudless Function context, which includes various information like the caller’s ID, timestamps, etc. Also, every input argument of the function is also accompanied with metainformation of its origins. The reasons behind this is the enforcement of security invariants and business rules on Compute Functions. The best practice is to ensure distributed security invariants based on the knowledge of the origin of the incoming arguments instead of whitelisting particular peer IDs or even Cloudless Functions which could exclusively be executed — while the latter is also possible.
Compute Functions cannot trigger Cloudless Functions as a part of their execution, as this would easily lead to amplification and DDoS. For example: a malicious function would issue a new request to trigger itself, leading to an infinite loop. That’s why it is prohibited by design and works only vice-versa: Cloudless -> Compute.
Managed Effects
In the cloud infrastructures of web2, serverless is often used to integrate managed services like DynamoDB or S3 with AWS Lambda and AWS Step Functions. With Fluence, interaction with both web2 services and web3 protocols can be established as long as they are exposed to the Fluence network as Compute Functions. Exposing external services into Fluence is implemented via Managed Effects.
Marine Wasm modules, as previously mentioned, serve as the delivery units for Compute Functions within a Cloudless Deployment. The ability to link these modules and reuse compiled modules as foundational elements for multiple Compute Functions provides Compute Providers with the flexibility to deem certain modules as safe, even if they aren't fully sandboxed.
The Managed Effects approach:
- Some Marine modules have effects that go out of the sandbox; such a module is called Effector Module.
- Effector Modules must be explicitly whitelisted by Compute Providers.
- Developers have the capability to construct diverse Compute Functions by utilizing the necessary effects, all made possible through Effector Modules and the module linking feature of Marine.
Managed Effects make Fluence Protocol a Swiss Army knife for the task of integrating web2 services and web3 protocols into a user facing products, removing the limits of Webassembly runtime and the boundaries of Fluence Network.
There are two ways to integrate external services: introduce a new Effector Module, or leverage the capabilities of existing ones.
An example of the first approach is the Fluence’s default IPFS Effector. It requires IPFS client binary to be deployed on the compute provider’s resources.
The second approach is illustrated in the effectors repository: the new integration is provided as a Marine service, which utilizes the existing cURL effector to interact with external nodes via an HTTP API. Therefore, to establish a connection with a protocol, a developer needs a Marine module that is linked to a cURL Effector.
Compute Providers may introduce new effects, wrap them with Effectors, and register to Compute Marketplace so that developers choose resources for their Cloudless Deployments that fit the best. Compute Providers could gain an advantage by offering extra features on their Fluence nodes. This could include providing access to other decentralized protocols, blockchain full nodes, or even exclusive services like databases and cloud services.
Application Composition
Fluence applications are created from the composition of described concepts: Cloudless Functions, Compute Functions, and Managed Effects. However, there are more tools to help implement popular engineering patterns.
Spells
Spell is a special service that aggregates a set of Compute Functions, a local key-value storage that developers can build upon, and a Cloudless Function — an Aqua script that is executed based on a cron-like trigger. Spells are usually run by Cloudless Scheduler in the Subnet and implement network protocols where state synchronization or event subscription is required (e.g. consensus).
Client calls
Cloudless functions can call not just Compute functions but interact with clients. For example, Fluence JS Client in your web browser can expose an API to show a notification with the result of a Cloudless Function.
Fluence’s cloudless approach offers exceptional flexibility and versatility both to the developers and compute providers. Combined together, Cloudless Functions, Compute Functions, and Managed Effects serve as a bedrock for the protocols and applications that build the future.
Fluence CTO Dmitry Kurinskiy walked us through the Fluence cloudless computing architecture in the podcast with Chad Fowler from Blueyard Capital, watch it here.
See our Glossary to learn more about Fluence concepts. Join our Telegram and Discord channels to ask anything and follow us on Twitter to stay up to date on all things Fluence!